2024年4月19日,主(zhu)題為「“融合(he)創‘新’,數‘智’賦能”—2024藝(yi)賽旗春季產品發(fa)布會(hui)」,在線上(shang)順(shun)利舉行(xing)!
2023 年,ChatGPT 火出了圈,繼 ChatGPT 之后,全球(qiu)各行各業大模型千(qian)帆競發。
在大模型的加持下,超自動化將會產生怎樣的“超能力”?
南京大(da)學人工智(zhi)能學院副院長、藝(yi)賽旗(qi)首席科學家(jia)黎銘(ming)教授在藝賽旗2024春季發布會上為我們了帶來主題為《基于大模型的流程自(zi)動(dong)化(hua)》的分享。
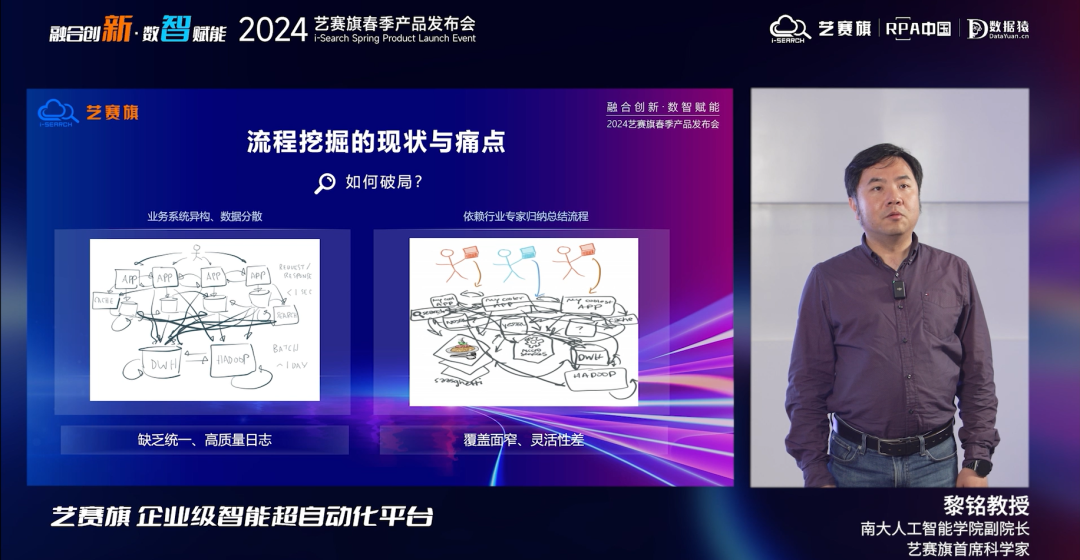
流程自動化的關鍵是要理清流程,在完成自動化之前,流程挖掘是非常重要的一步。
企業不管是要做數字化轉型,還是要提升經營效率,首先都需(xu)要對整個公司(si)的(de)業務進行(xing)實時(shi)客觀(guan)的(de)觀(guan)察和了解。
由于大部分企業的內部涉及多個異構的業務系統,數據往往分散在多個系統中,難以給出一個統一的高質量日志文件。
此外即便通過流程挖掘發現了業務流程中的瓶頸,優化建議的執行和效果驗證仍然依賴于人員進行,這需要和用戶頻繁溝通了解訴求,不同視角的人總結出來的流程可能存在差異,反饋的時間可能較長,帶來大量溝通成本,最終導致項目難以推進。
黎教授指出,機器學習是利用經驗來提高系統性能的一種技術,它可以從業務數據中自動發現、配置并運行流程,并根據業務條件與變化對自身進行適時調整。機器學習研究的主要產物是算法,這些算法可以在各個行業有廣泛應用,包括計算機視覺、人工智能和數據挖掘。
現如今機器學習已經成為人工智能領域的核心研究之一,在各個領域中展現出巨大的潛力和創新能力。計算機領域的(de)(de)最高(gao)獎(jiang)——圖靈獎(jiang)就連續授(shou)予了(le)這方面的(de)(de)學者。
除了學術界,政府和工業界也對機器學習給予了高度重視,我國在《新一代人工智能發展規劃》里,將機器學習列為需重點研究的關鍵基礎理論之一,美國白宮印發的人工智能白皮書,也將其列為人工智能領域最重要技術之一。
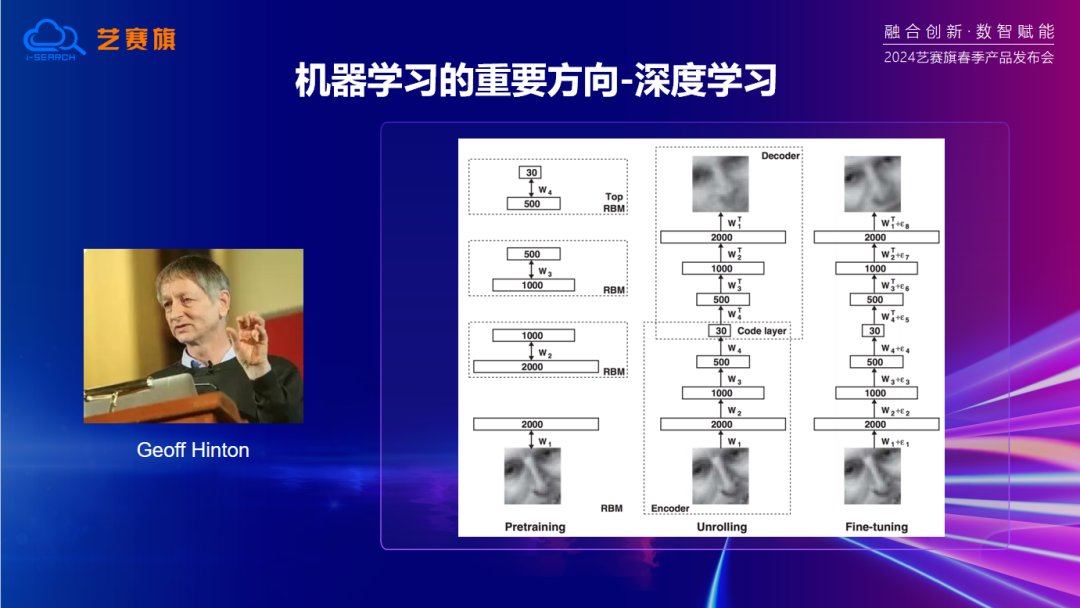
機器學習是隨著人工智能發展而興起的,到了 90 年代開始逐漸受到重視。機器學習的一個重要分支方向是深度學習,由學者 Jeffrey Hinton 在 2006 年提出。深度學(xue)習(xi)(xi)的(de)發展使得機器學(xue)習(xi)(xi)模型能夠解決更(geng)復雜的(de)問(wen)題,例如2016年基于深度學習模型的AlphaGo 就打敗了人類頂尖棋手,引起了全世界的轟動。
到了2022年底,基于深度學習模型的ChatGPT誕生,再次引起了廣泛關注,ChatGPT驗證了大模型的巨大商業價值和科研價值。ChatGPT不僅是一個對話機器人,它還在機器翻譯、問答系統、創意寫作、搜索和閱讀理解等方面取得了許多成功案例。
為了(le)提高模型的推理能力,OpenAI在2021年(nian)利用179G的代(dai)碼數據對GPT3進行訓練,希(xi)望通過(guo)這種訓練提升模(mo)型的邏輯推理能力。
既然模型已經開始用代碼進行訓練,那么人們就開始思考 ChatGPT 這樣(yang)的預訓練模(mo)型是否可以更(geng)好地用(yong)于軟件開發?
我們很早就開始了在這方面的思考,針對代碼(ma)的局部領(ling)域(yu)關(guan)系(xi)(xi)、線性依賴關(guan)系(xi)(xi)、語法依賴關(guan)系(xi)(xi)、控制依賴關(guan)系(xi)(xi)、多(duo)層次結構交互關(guan)系(xi)(xi)等進(jin)行了研究,提出了多(duo)種學習模型。
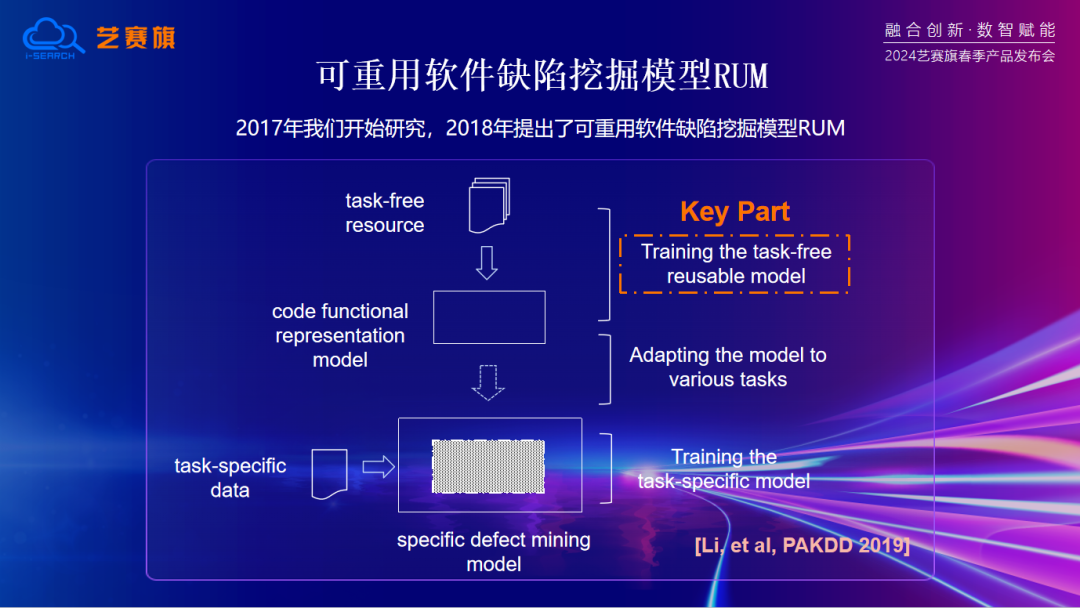
研究過程中遇到了數據量不足的問題,難以支撐訓練出一個比較好的深度模型。因此,我們開始在網上獲得大量代碼信息,做出一個通用的代碼表征模型,并通過代碼復用技術,將其應用到各個任務中,從而獲得更好的性能。
因此我們提出了一個基于模型復用的框架,基于此(ci)框架訓練(lian)出一個可重用的軟件缺(que)陷(xian)挖掘模型RUM,并將(jiang)其應用(yong)(yong)于不(bu)同的缺陷挖掘任務(wu)中(zhong)。這(zhe)是(shi)最早的使用(yong)(yong)預訓(xun)練模(mo)型來(lai)解決不(bu)同任務(wu)的思考模(mo)式,也(ye)為后續的研究方向奠定了(le)基礎。
ChatGPT就是這樣一個經過語言和代碼訓練的通用模型,在軟件開發過程中的具有很大的應用潛力。工業界對此也有深入的跟進和思考,如Microsoft和OpenAI聯合開發的GPT代碼生成模型CoPilot,以及GitHub和OpenAI合作開發的代碼生成模型Codex,都在代碼生成領域取得了顯著的成功。
在使用ChatGPT的過程中,它展現出了強大的語言和邏輯推理能力,能夠輔助開發者編寫高質量的代碼。例如,當需要編寫一個Python版本的快速排序代碼時,ChatGPT可以直接生成代碼,并附帶對該代碼的解釋。
然而,當涉及到業務代碼時,ChatGPT的性能就會受到挑戰。在自動化流程挖掘中,生成相應的流程挖掘代碼是一項關鍵任務,這需要解決ChatGPT在業務代碼編寫方面的短板。
第一個挑戰是 ChatGPT 對語言的過度依賴。作為一個基于語言的模型,ChatGPT在分析代碼(即編程語言)時會遇到困難,因為編程語言和自然語言存在顯著差異。盡管編程語言可以通過程序員的要求提高代碼的可讀性,但這并非強制性的。換言之,即使代碼的可讀性較差,它仍然可以正常運行。因此,如果用ChatGPT這樣的模型去分析這樣的代碼,可能會導致錯誤。
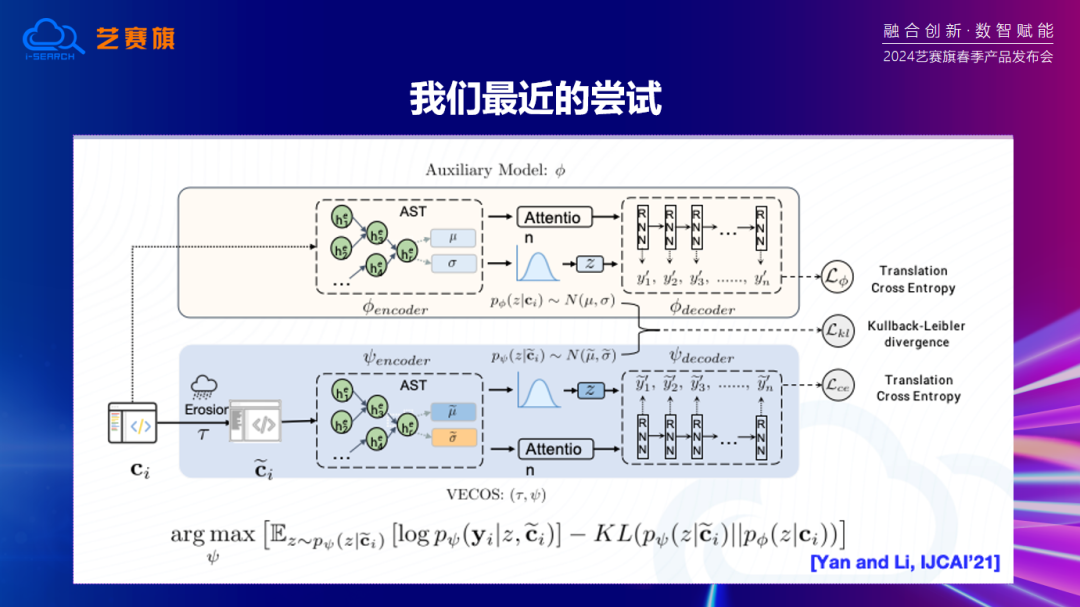
為(wei)此,我(wo)們(men)提(ti)出了一個相應(ying)的嘗試性(xing)解決(jue)方案—— VECOS。這個模型可以對質量非常低的,甚至是反編譯出來的代碼進行語義分析和理解。
另一個挑戰是雖然 ChatGPT 對語言文字很敏感,但對編程語言的功能語義建模能力有限。
對此,黎教授舉例說明,有兩段 Java 代碼,可能在詞匯表級別完全一致,但實際功能和語義卻有顯著差異。這是因為在程序設計中,程序結構中的內在關系尤為重要。如果要生成或理解代碼的功能,就需要對這部分進行有效建模。然而,目前的ChatGPT模型只抓住了文字層面的關系,卻忽略了程序內蘊的結構聯系。因此,需要對相應的程序結構語義進行特殊的建模。
針對這一問題,我們開始探討如何在以Transformer為基礎模型的預訓練大模型上考慮代碼結構特征?
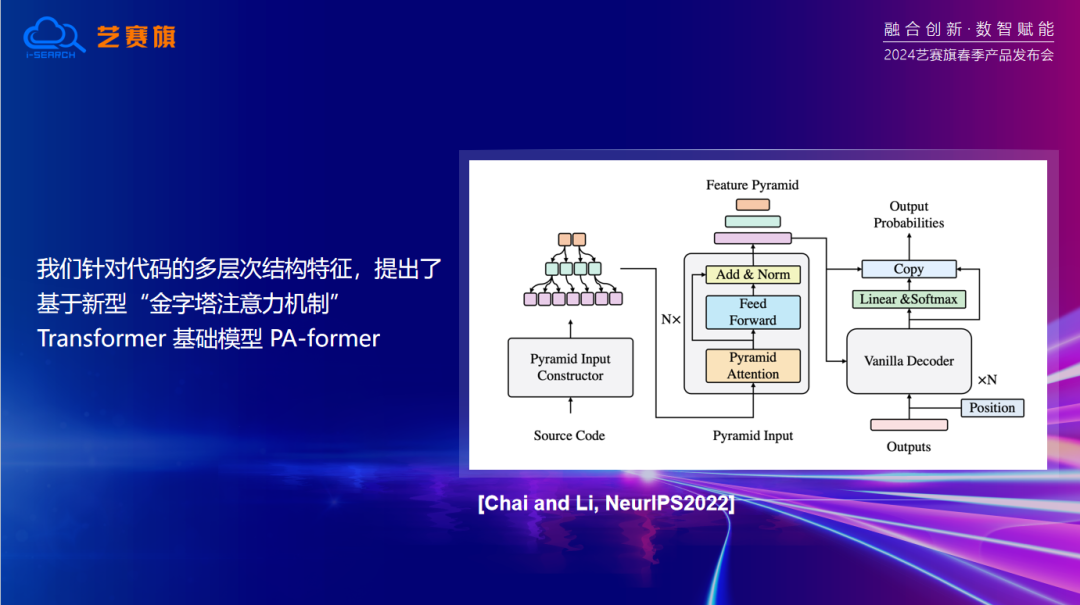
Transformer是目前最先進的神經網絡結構之一。它通過自注意力機制,能夠捕捉到輸入序列中的長距離依賴關系,從而實現對復雜語義的理解。這種強大的能力使得ChatGPT能夠處理各種復雜的自然語言任務,包括問答、文本生成、摘要等。并且針對代碼的多層次結構特征,我們提(ti)出(chu)了基(ji)于(yu)新型“金字塔注意力機制” Transformer 基(ji)礎(chu)模型 PA-former。
以上所述的基礎理論方法和技術已被應用到實際業務場景中,包括藝賽旗(qi)的(de)流程挖掘技術及業務場(chang)景,以(yi)幫助其(qi)更好(hao)的(de)進行(xing)業務流程的(de)發(fa)掘。
南京大學與(yu)藝賽(sai)旗共同發起(qi)的智(zhi)能研(yan)究院在人工智(zhi)能及超自動化領(ling)域的研(yan)究成果,充(chong)分展現(xian)了其卓越的創新能力(li)。這些研(yan)究成果不僅(jin)在學術界受到高度認可,也在實際應(ying)用中取得(de)了顯著的成果。隨著科技的不(bu)斷(duan)進步(bu)和發(fa)展(zhan),相信這些(xie)成(cheng)果將在(zai)更多(duo)領域發(fa)揮重要的作用。
 企業平臺
企業平臺 發現評估
發現評估 自動化
自動化 行業解決方案
行業解決方案 通用解決方案
通用解決方案 合作伙伴
合作伙伴 生態聯盟
生態聯盟 咨詢服務
咨詢服務 培訓服務
培訓服務 交流社區
交流社區 客戶成功
客戶成功 公司介紹
公司介紹 新聞列表
新聞列表 聯系我們
聯系我們 加入我們
加入我們